
서버가 다운되었습니다. 부랴부랴 로그를 확인하고 모니터링 시스템의 그래프를 열어봅니다. 하지만 그래프는 평온합니다. CPU 사용량은 평균 20%로 표시되어 있고, 메모리도 넉넉했습니다. 도대체 무엇이 문제였을까요? 우리는 이 현상을 “1분의 공백”이라고 부릅니다. 대부분의 기존 모니터링 도구가 1분 또는 5분 단위의 평균값을 보여주기 때문에, 그 사이에 발생한 10초간의 치명적인 스파이크(Spike)를 놓친 것입니다.
오늘 소개할 Netdata는 이러한 “평균의 함정”을 완벽하게 깨부수는 차세대 실시간 모니터링 솔루션입니다. 수억 원대의 상용 EMS(Enterprise Monitoring System)를 걷어내고, 비용 0원으로 압도적인 가시성을 확보하는 방법을 엔지니어의 관점에서 심층 분석해 드립니다.
🚀 왜 지금 Netdata인가?
IT 인프라는 점점 더 복잡해지고 빨라지고 있습니다. 컨테이너는 수초 만에 생겼다 사라지고, 마이크로서비스 간의 통신은 복잡하게 얽혀 있습니다. Netdata는 “설치 후 10초 만에 시각화된 데이터를 본다”는 철학 아래, 전 세계 엔지니어들에게 새로운 표준을 제시하고 있습니다.
1. 1초의 미학: High-Resolution Monitoring
Netdata의 가장 강력한 무기는 데이터의 해상도입니다. 기존의 Zabbix나 Nagios가 망원경으로 숲을 보는 도구라면, Netdata는 현미경으로 세포의 움직임을 관찰하는 도구입니다.
- 초단위 수집 (Per-second Granularity): 모든 지표를 1초 간격으로 수집합니다. 순간적인 CPU 튀는 현상, 디스크 I/O 병목 등을 놓치지 않습니다.
- 수천 개의 지표 자동 감지: OS 커널, 네트워크 스택뿐만 아니라 MySQL, Nginx, Redis, Docker 등 실행 중인 애플리케이션을 자동으로 감지하여 차트를 생성합니다. 설정 파일과 씨름할 필요가 없습니다.
2. eBPF: 인프라의 MRI를 찍다
단순히 CPU가 높다는 사실만으로는 문제를 해결할 수 없습니다. “왜 느린가?”에 대한 답이 필요합니다. Netdata는 리눅스 커널 기술의 정점인 eBPF(Extended Berkeley Packet Filter)를 활용하여 애플리케이션의 코드를 수정하지 않고도 심층 분석을 수행합니다.
💡 eBPF가 보여주는 것들
1. VFS Latency: 디스크 읽기/쓰기가 0.1초 이상 걸리는 ‘느린 요청’이 몇 건인지 정확히 집계합니다.
2. Process Lifecycle: 0.01초 만에 실행되고 사라지는 단기 프로세스(Short-lived process)까지 추적하여 CPU 부하의 원인을 밝혀냅니다.
3. TCP Sync: 네트워크 연결 과정에서의 미세한 지연과 패킷 드롭을 커널 레벨에서 감시합니다.
3. Zabbix vs Netdata: 대체가 아닌 상생
많은 분들이 묻습니다. “Zabbix가 있는데 Netdata가 필요한가요?” 결론부터 말씀드리면, 두 도구는 역할이 완전히 다릅니다. 성공적인 운영팀은 두 가지를 하이브리드로 사용합니다.
| 구분 | Zabbix + Grafana | Netdata |
|---|---|---|
| 핵심 철학 | 가용성 관리 (Up/Down 확인) | 성능 분석 및 트러블슈팅 |
| 데이터 주기 | 1분 ~ 5분 (트렌드 파악) | 1초 (실시간 정밀 분석) |
| 접근 방식 | Top-Down (관리자가 설정) | Bottom-Up (자동 감지) |
| 추천 용도 | 전체 관제, 장기 리포팅 | 장애 원인 분석, 실시간 대응 |
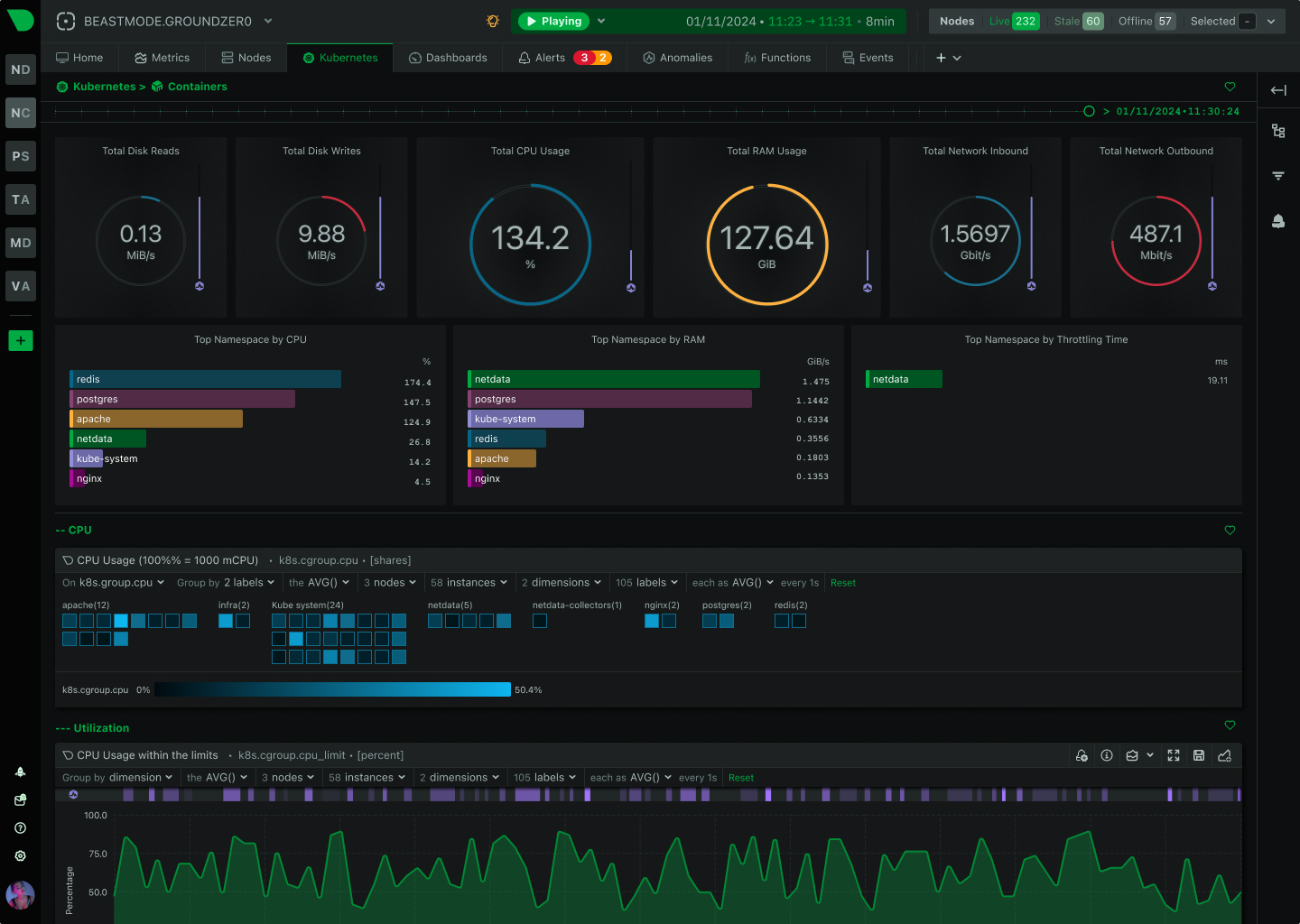
평상시에는 Zabbix로 전체 숲을 보고, 알람이 울리면 Netdata 링크를 클릭해 1초 단위의 과거 데이터를 복기하며 장애의 ‘진짜 원인’을 찾아내는 워크플로우가 가장 이상적입니다.
4. 엔터프라이즈급 구축 전략: 비용 0원의 기적
물리 서버 10대, 가상화 서버 30대, PC 100대 규모의 인프라를 상용 솔루션으로 구축하려면 수천만 원의 라이선스 비용이 듭니다. 하지만 Netdata는 오픈소스이며 무료입니다. 다음과 같은 아키텍처로 엔터프라이즈급 환경을 구성할 수 있습니다.
아키텍처: Centralized Streaming
170여 대의 노드를 효율적으로 관리하기 위해 Parent-Child 구조를 제안합니다.
- Parent Node (중앙 서버 1대): 모든 데이터를 수신하고 저장하며 알람을 발송하는 컨트롤 타워입니다. RHEL 기반 서버에 4 vCPU, 16GB RAM 정도면 수백 대의 노드를 감당할 수 있습니다.
- Child Nodes (대상 서버): 데이터를 디스크에 저장하지 않고 Parent로 스트리밍만 합니다. 운영 서버의 부하를 ‘0’에 가깝게 유지할 수 있습니다.
- SNMP & Proxy: 에이전트 설치가 불가능한 네트워크 장비는 SNMP로 수집하고, 보안을 위해 DMZ 내부의 Proxy 서버를 경유하여 외부로 알람을 보냅니다.
5. 알람의 혁신: 네이트온 & 텔레그램 연동
이메일 알람은 묻히기 쉽고, SMS는 비용이 듭니다. Netdata는 Webhook을 통해 네이트온, 텔레그램, 슬랙 등으로 실시간 알람을 무료로 발송할 수 있습니다. 특히 폐쇄망 환경에서도 Proxy 설정을 통해 안전하게 외부 메신저와 연동이 가능합니다.
custom_sender() { # DMZ 내 프록시 서버 설정 local proxy=”http://192.168.10.99:3128″
# 네이트온 팀룸으로 메시지 전송
local message=”[Netdata Alert] ${host} ${status_message} – ${info}”
# -x 옵션으로 Proxy를 경유하여 전송
curl -x “${proxy}” -X POST \
–data-urlencode “content=${message}” \
“[https://teamroom.nate.com/api/webhook/YOUR_KEY](https://teamroom.nate.com/api/webhook/YOUR_KEY)”
}
이 간단한 스크립트 하나로, 엔지니어는 퇴근 후에도 스마트폰으로 서버의 상태를 1초 만에 파악할 수 있게 됩니다. 이것이 바로 진정한 Obsesrvability(관측 가능성)의 확보입니다.
결론: 모니터링, 이제는 관측의 시대로
Netdata는 단순한 툴이 아닙니다. 엔지니어에게 시스템을 꿰뚫어 볼 수 있는 ‘새로운 눈’을 제공합니다. 서버가 느려질 때마다 “재부팅 해볼까요?”라고 말하는 대신, “10시 5분에 백업 프로세스가 디스크 I/O를 100% 점유했네요.”라고 정확히 말할 수 있는 전문가가 되고 싶다면, 지금 바로 Netdata를 도입해 보십시오.
🚀 지금 바로 시작하세요
복잡한 기획서는 필요 없습니다.
지금 당장 가장 골치 아픈 서버 한 대에 Netdata를 설치해 보세요.
그동안 보이지 않던 시스템의 심장 박동 소리가 들리기 시작할 것입니다.